Archive
Note
The following things should be restructered when updating the whole tutorial.
Octomap on External Computer
This page will help you to make and save an Octomap on your external computer.
Requirements
You have to be able to run rviz on your external computer.
Clone the franka_constrained_control project or make a new catkin workspace on your external computer.
Install the ROS Octomap packages on your external computer
sudo apt-get update sudo apt-get install ros-melodic-octomap ros-melodic-octomap-server ros-melodic-octomap-mapping ros-melodic-octomap-ros ros-melodic-octomap-msgs
Create a package for the Octomap on the external computer
Why not clone zed-interfaces and zed-ros-examples in catkin_ws/src on external computer??
Download the folowing zip file:
Unzip and drag the files in your
catkin_ws/srcdirectorybuild your catkin workspace
cd ~/catkin_ws catkin_make
Vizualize the Octomap in rviz
You can first modify the Octomap parameters to your requirements.
Go to the launch directory in the octomap_tools package, which you can find in
cd path/to/catkin_ws/src/octomap_tools/launch
In the file
save_octomap_from_pointcloud.launchyou can modify the Octomap parameters that are explained in Section 2.2.4.
Once the ROS network is established, vizualize the Octomap in rviz.
Open a new terminal on the external computer and run
roscore
Open a new terminal on the Jetson and run
roslaunch zed_wrapper zed2.launch
Open another terminal on the external computer and run
cd path/to/catkin_ws source devel/setup.sh roslaunch octomap_tools save_octomap_from_pointcloud.launch
Finally you should see something like this:

Save an Octomap and visualize an existing Octomap
You can save the Octomap vizualized in rviz while rviz is still running. Therefore you have to go to the directory where you want to save the Octomap and run the octomap_saver server with the name you want to give to the Octomap.
cd path/to/octomap-directory/
rosrun octomap_server octomap_saver -f <octomap-name>.bt
To vizualize a saved Octomap, you have to run on your external computer
roslaunch octomap_tools load_octomap.launch path:=path/to/octomap-directory/<octomap-name>.bt rviz_octomap:=true
Setup the ZED camera with Panda Arm
Ethernet connection between Panda Arm’s computer and Jetson
Make a ros network between the Jetson and the panda computer but with the IPs 192.168.4.65 for the computer and 192.168.4.66 for the Jetson otherwise the robot would not work.
Download and build the ROS package
Clone the ROS package we made on the computer in the directory you want:
cd path/to/your/directory
git clone https://github.com/panda-brubotics/franka_constrained_control.git
Do the steps in the README file to build it.
Objects detection with ZED2 in Panda arm environnement
What does this program ?
Modify parameters in the launch file
Go to the zed_franka_planner package, in the launch directory open the file
grab_detected_object_test.launchwith your favorite editorFrom here you can change some parameters
The parameter
object_to_be_detectedcan be one of the listed here
Launch the program
On the computer run
roscoreOn the jetson run
roslaunch zed_wrapper zed2.launchOn the computer and in another shell source the workspace and launch the program
cd path/to/your/folder/franka_constrained_control/catkin_ws source devel/setup.sh roslaunch zed_franka_planner grab_detected_object_test.launch
Once rviz is launched, load the parameters saved in the file
path/to/the/package/zed_franka_planner/rviz/zed_panda_object_tracking.rviz
Modify the camera transformation parameters
The panda robot’s axis are:

The map frame’s origin is the position of the camera when you launch the zed_wrapper node on the jetson and its axis are:
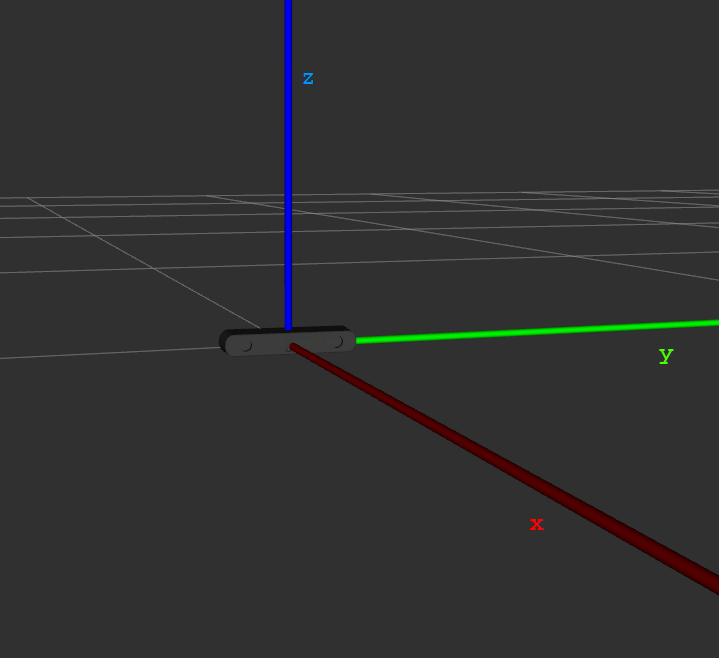
To modify the transformation between the camera and the robot:
Go to rviz
From the display
Static Transform Publisheryou can set the map and robot frames and the transformation parameters:
Octomap for Panda arm
This section will help you to make and save an octomap of the panda arm environnement
Parameters for the octomap
Set parameters to filter the pointcloud
In this section we will set the parameters used to filter the point cloud so we can create an octomap from the filtered point cloud In the filterd point cloud, the robot is removed
When you are in your
catkin_wsdirectory go tosrc/franka_ros/panda_moveit_config/configOpen the file
sensors_kinect_pointcloud.yamlFrom this file, you can change some parameters (source : Perception Pipeline Tutorial):
The general parameters are:
sensor_plugin: The name of the plugin that we are using.
max_update_rate: The octomap representation will be updated at rate less than or equal to this value.
Parameters specific to the Point cloud updater are:
point_cloud_topic: This specifies the topic to listen on for a point cloud.
max_range: (in m) Points further than this will not be used.
point_subsample: Choose one of every point_subsample points.
padding_offset: The size of the padding (in cm).
padding_scale: The scale of the padding.
filtered_cloud_topic: The topic on which the filtered cloud will be published (mainly for debugging). The filtering cloud is the resultant cloud after self-filtering has been performed.
Set the octomap parameters:
Go to the octomap_tools package
Go to the launch directory
Open the file
save_panda_octomap.launchFrom this file you can change some parameters (lines 22 to 25)
The parameters are listed and explained here in the section 2.2.4
Create and save the octomap
Go to your catkin_ws source your workspace and run the program
cd path/to/your/workspace
source devel/setup.sh
roslaunch octomap_tools save_panda_octomap.launch
In rviz load the config localized in the package
zed_franka_plannerin rviz/zed_panda_save_octomap.rvizAdjust the transformation between the camera and the robot by using the
Static Transform Publisherin rvizWrite down the transformation in quaternion
Once you get a satisfying octomap, you can save it:
Go to the directory where you want to save the octomap
Open a terminal there
Run
rosrun octomap_server octomap_saver -f panda_robot_octomap.bt
Plan in the octomap environnement

Go to your catkin_ws source your workspace and run the program
cd path/to/your/workspace
source devel/setup.sh
roslaunch zed_franka_planner plan_in_octomap.launch path:=path/to/your/saved/octomap panda_to_map_transfo:="1.3 0.06 0.38 0 0 1 0"
# "1.3 0.06 0.38 0 0 1 0" is the transformation in quaternion between the camera and the robot when you saved the octomap
In rviz load the config
plan_in_octomap.rviz(same directory as earlier)
Training a Neural Network for Object Detection
Purpose of the object detection
Here we will explain why we need a custom 3D object detection AI and which model we use.
One task for the robot arm is to grab objects and to move them from a location to an other one. So we can specify in the code the position of the objects in order to grab them, but we want to get the position automatically with a camera. So we need object detection. Stereolabs has already implemented a 3D object detection with its ZED camera, but the objects detected are limited and the code is close so we can’t customize it. We need to detect some cubes, so we need our own object detection.

In order to detect object, we need to find a pre-existing model which allows us to do 3D object detection. We choose the frustrum-pointnets model, which first perform 2D object detection, and then 3D object detection using the 2D object detection.
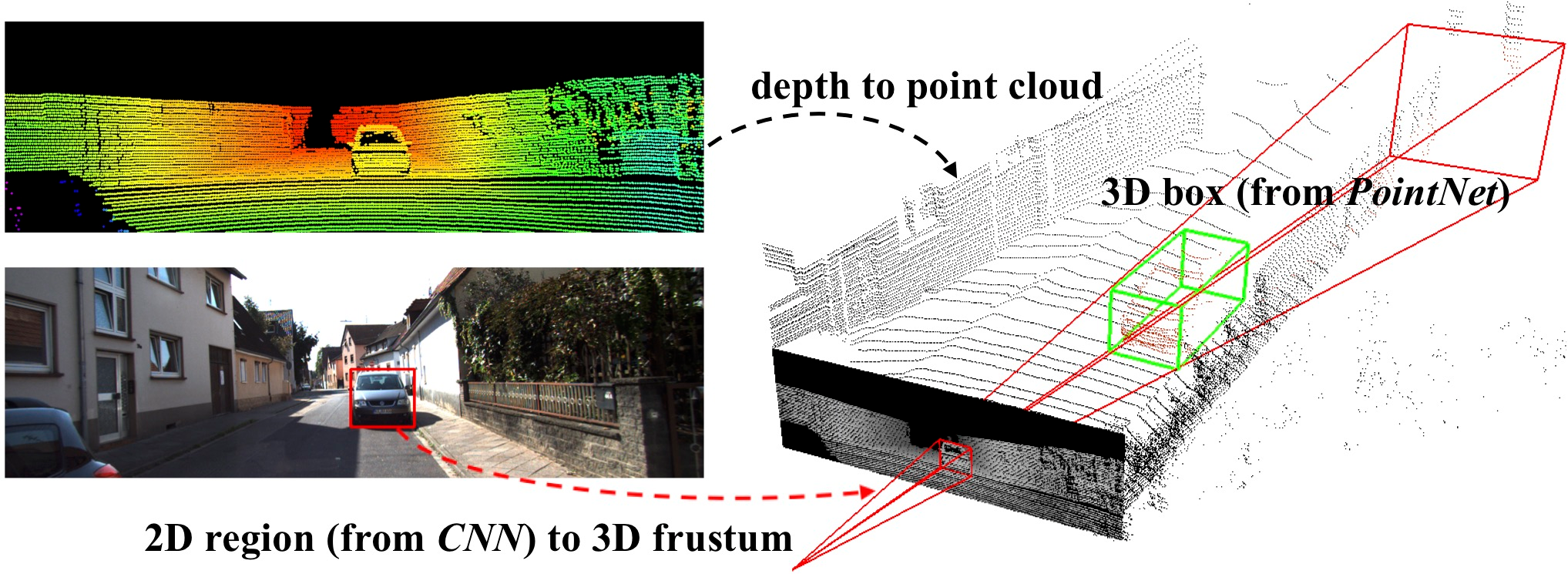
We tried the code with the KITTI database and it worked well, so we decided to create our own data with the same convention as the KITTI database, and then train the model. We need the RGB image, the pointcloud and the label file to train the model.
Saving the data
Here we will explain how to save the data you need in order to train the AI.
For saving the data, you will need :
A computer with an Nvidia GPU (the Jetson must be ok only for grabbing data!)
A ZED 2 camera (need to be plug-in a computer with Nvidia)
The labelCloud tool
git clone https://github.com/ch-sa/labelCloud.git cd labelCloud pip install -r requirements.txt
The Frustum PointNets software.
We are currently using a modified version of this repository four our purpose
git clone https://github.com/panda-brubotics/object_detection.git
Saving data (rgb images, pointclouds and transformation files)
The time need for this step depend on your setup (camera and object placement) / how fast you are to move the camera between two photo shoots and how many shoots you want to take. It took us approximately 15 minutes to grab 100 pictures.
Labeling part:
This part is the longest and the hardest one. The time required to label depends on the quality of the pointcloud since we have to identify the object we want to label in it. If we can not clearly see the object in the pointcloud then we will have to use the 2D image that corresponds to it to estimate his position in the pointcloud.

For our first 100 images, it took us 2h20 to label 50 images person. We managed to reduce the time to label 100 images per person to approximately 1h. If you do not want to waste a lot of times with labeling here some tips to have a good start.
Training part:
The training part takes 4 hours for 8000 images
Advice:
Before starting to save your data with the ZED2, use a tripod to position the camera. Put the camera at least 50cm from where you are going to take the picture. The camera has to be in an horizontal direction during the whole process (try not to lean the camera when you take pictures of the objects for easier labeling). Between two picture move the camera slightly (by 5cm or 10cm). During the process DO NOT MOVE YOUR OBJECTS OR IT WILL BE HARDER FOR LABELING. Follow this step will reduce significantly the time spent on labeling.
Saving data:
To save the data with the ZED 2 camera, you have to clone the perception_pcl from this repository which contains the rgb_pointcloud_saver code you will use to save your data.
cd path/to/catkin_ws/src
git clone https://github.com/panda-brubotics/rgb_pointcloud_saver.git
cd ..
catkin_make
In order to launch the file, execute these two lines in two different terminals. In the first terminal you will have to launch the zed_wrapper. You can get it in the wrapper. But before that go to the zed wrapper configuration directory and open the common.yaml file
cd path/to/catkin_ws/src/zed-ros-wrapper/zed_wrapper/params
gedit common.yaml
At line 32 set self_calib to false to disable the camera calibration.
Now you can execute the wrapper
roslaunch zed_wrapper zed2.launch
It is better if you save all the data in the labelCloud directory. To do this make sure you have cloned the labelCloud repository. Now open a second terminal and go in the labelCloud directory to run the rgb_pointcloud_saver code.
cd path/to/labelCloud
rosrun pcl_ros rgb_pointcloud_saver number_of_the_first_image_to_take number_of_images_to_take
Every time you press enter, the program will take a new picture and display how many picture you took. You can quit whenever you want by pressing q.

Here are the outputs of rgb_pointcloud_saver:
2 .jpg files:
the left and right images from ZED2 camera.
1 .pcd file:
a colored 3D binary point cloud from ZED2 camera
1 .json file:
a transformation file which contains the transformation made by the camera between two camera shoots.
Note
Do not forget to move the camera between two pictures, but when taking a picture do not move the camera or the picture will be blurry.
Label the data
We created a program named deduce_labels.py that helps us to label the pointclouds. Download it and put it in the labelCloud directory.
cp /path/to/Downloads/deduce_labels.py /path/to/labelCloud/
Before starting to label your data you can take a look at the config.ini file. In this file you can configure your keyboard and mouse setting. This will help you to be more efficient while labeling your pointcloud.
cd path/to/labelCloud
gedit config.ini
Here a configuration file we used.
Now you can label your data. For this go in your labelCloud directory and run the labelCloud.py code.
cd path/to/labelCloud
python3 labelCloud.py
Make sure to perfectly label the object you want to detect in the pointcloud (do your best). Do not forget to change the name of the object you label on the right of the software. Press “save label” on the bottom left of the software once you finished to label the object.

Now in an other terminal go in your labelCloud directory and run the deduce_label.py code. This code will deduce the position of the future bounding box based on the labels from the previous pointcloud and the transformation file (this transformation file contains the translation and the rotation made by the camera between two pictures).
cd path/to/labelCloud
python2 deduce_label.py number_of_the_image_you_labeled 0 #(0 for the first image) precise the current pointcloud
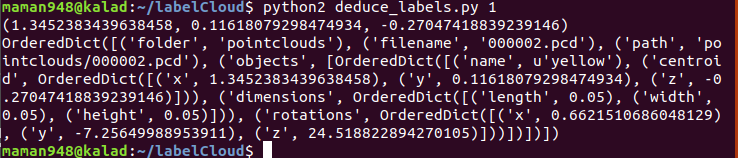
Now click next on the upper left corner, and you will see the next pointcloud with the predicted bounding box using the camera movement. So now you can adjust the bounding box. Repeat this process for every pointcloud.
Note
deduce_label.py does not predict at 100% the bounding box should be. 70% of the time the predicted bounding box does not fit the object so you will have to adjust it manually.
Convert data for training
Now that you have all the data needed for training, we need to convert them and put them into the frustum pointnets directory . So we created a little script for you to use to convert your data. You can get everything from this github repository. This repository also include the frustum pointnets software. Here the link to the frustum pointnets github repository if you want to take a look at it.
Now that you have clone this repository, there are still some change to make. First of all, you have to get the ZED2 camera calibration file, which is located here :
cd /usr/local/zed/settings
Open the .conf file, and in the LEFT_CAM_HD section, copy the cx, cy, fx and fy (line 46, 47, 48, 49) and replace the cx, cy, fx, fy variable in the calib.py in the convert folder. Then now go in the convert directory execute the convert.sh script. This script will convert in the right format every files needed for the AI training.
cd path/to/3d-object-detection/frustum-pointnets-master/convert
bash convert.sh path/to/labelCloud ../dataset/KITTI
- This script will generate:
the calibration files
convert .pcd to .bin file
convert label
copy the rgb images
image_sets files
create rgb_detection files
Changing files in frustum-pointnets
As explained before, we changed files in the frustum pointnets github in order to make it work.
- Here are the files which were changed :
kitti/kitti_object.py
kitti/kitti_util.py
kitti/prepare_data.py
mayavi/test_drawline.py
models/frustum_pointnets_v1.py
models/model_util.py
models/tf_util.py
train/box_util.py
train/provider.py
train/test.py
train/train.py
train/train_util.py
If you want to train a custom model, you have to change some files from the frustum directories. Search for yellow, green and purple to replace them with your object names
Training the AI
Here we will explain how to train the neural network.
Now that everything is set up, we will train our AI. As it is explained in the Readme of frustum-pointnets, execute the following commands :
sh scripts/command_prep_data.sh
CUDA_VISIBLE_DEVICES=0 sh scripts/command_train_v1.sh
You will see a window like this one appear :

The training will try to reduce the mean loss. The loss represents the error between the prediction and the label. So the lower it is, the better it is. At a certain moment, you will see that the loss does not move : the algorithm can’t learn more, you can stop it.
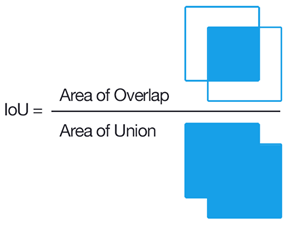
Also, take a look at the IoU (which represents the the intersection divided by the union of the label and the predicted bounding box from the AI). It varies from 0 to 1. If it is 0, the two boxes do not overlap. If it is 1, the two boxes exactly match.
Also, if you want to upgrade the number of data, you can update the convert.sh script by taking in account the right images, so you can double the data you have
Now, you just try to predict the labels :
sh scripts/command_test_v1.sh
The results of this command will be stored in the train/detection_results_v1/data/ folder You can visualize the results by swapping the labels files in the dataset/KITTI/object/training/label_2/ folder with those in the train/detection_results_v1/data/ folder. Then, execute :
python3 scripts/kitti_object.py
You can see if the network performs well on the data it trained on

